The following people participated in this workshop and contributed to the writing of this report: Urs Andelfinger, Melanie Chams, John Dilley, Filip Evenepoel, Bill Hasling, Thomas Koch, Echart Koppen, Michael Kran, James Megquier, Bob Moe, Mehran Moshfeghi, Saroj Sabherwal, Mike Spreitzer, Rachael Sokolowski, Jeff Sutherland, Gabor Szentivanyi, Joel Thibault, Anders Tornquist, Andrew Watson. Special thanks goes to the brave few who helped in summarizing the results: Mike Spreitzer, Thomas Koch, Echart Koppen, Filip Evenepoel and James.
Abstract
The Internet world is being transformed before our eyes as open standards such as XML are being rapidly adopted. The XML technologies are being seen as harbinger of various new functionality in numerous domains ranging from electronic commerce to electronic publishing to healthcare delivery to manufacturing to insurance. Various object-oriented technologies and standards such as Java, CORBA and DCOM have also progressed rapidly in the past few years. At this time, the industry and academia are seriously looking at the intersection of these technologies and what it means to the future of the object-web paradigm. This workshop aims to bring together participants who are seriously investigating the combined use of these technologies to support practical application needs in a variety of domains. The goal of this workshop is to investigate how XML and Distributed Object technologies such as Java, CORBA and DCOM can be integrated leveraging the strengths each have to offer.
1 Introduction
The workshop discussion focussed on a number of themes related to XML and Distributed Object Technologies (DOT). In particular, the relationship between XML, DOT and software modeling languages such as UML. We first report on the discussions related to the relationship between programming languages, modeling languages, interface description languages and data representation languages. Then we provide a summary of the discussion related to what tools are needed to facilitate building in XML and DOT environments. The following section provides a summary of various discussion themes as a simple FAQ. No report is complete without an alphabet soup, and this field is littered with innumerable three and four letter acronyms!
2 Desired Standards Developments
An issue of immediate practical concern is how to convert between XML and other data representations. For example, there are already systems that do RPC using an XML-based serialization of the data. There are tools for converting between Java objects and XML. The OMG is working up an RFP for a mapping from XML schemas to IDL. The list goes on.
The workshop participants were particularly interested in representations specialized to the data types at hand, rather than generic representations. That is, rather than simply using a Java presentation of the DOM to access any XML, it would be convenient for an application's XML schema (whether DTD, SOX, DCD, or whatever) to have an equivalent Java data type.
It would be desirable for there to be a standard notion of equivalence among these representations. However, it should be pointed out that, each of the representation, works at different abstraction levels. A general purpose programming language, such as Java, supports encoding of control, data and behavior. Interface Description Languages has no programming connotations, but they do support the representation of data and behavior. XML, on the other hand, supports data representation. So, when we are looking for equivalence of representation, here, we are only talking about data equivalence. That is, one could start with a datum in any one of these representations, convert to a different representation, and then convert back, getting the same datum that was started with. However, these representations are different enough that attempting this directly is problematic. At least the following two problems appear. First, each representation typically lacks some information that is relevant to the other(s) or the conversions. Put another way, there is ambiguity in each representation. Second, it is desirable to be able to convert any datum of each of the representations into each of the other representations. Without special care, however, each mapping is likely to be into, not onto, the target representation --- which means there are target data that have no equivalent source data.
Some of the attendees familiar with UML suggested that it can provide the basis of a solution to the above problems. The idea is outlined in the following diagram.
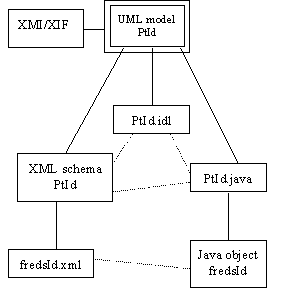
The idea is to focus on an application's UML models. A given model (e.g., PtId, for "PatienT ID") can be converted into IDL, and into Java and other programming languages. Suppose a given model can also be mapped to an XML schema. This establishes equivalences between application-specific XML types, IDL types, Java types, and so on. A given instance can be translated from one representation to another based on the equivalences between types. XMI from OMG and XIF from Microsoft are alternate ways of exchanging UML models.
There was a discussion of whether HL7 messages could participate in this solution, and the consensus is that they could. An HL7 message is defined by two equivalent representations, a "MIM" and a table. Both are representations of a particular UML model; thus an HL7 message type can participate as a UML model.
The ambiguity problem is solved because the UML model supplies the missing information.
This solution can handle any datum of a given participating representation iff there is a UML model that maps to any given (including user-defined) type of the given representation. It was asserted that this is so for IDL and Java. It was further asserted that this would be a reasonable thing to ask of the XML Schema language now being developed by a W3C Working Group.
3 Desired Tools Developments
3.1 Editors
The discussion of requirements for editors revealed complex requirements that shaded into the area of integrated development environments (IDEs) such as have been developed for full-scale programming languages.
At the low end of the scale was the need for simple WYSIWYG editors for XML documents and editors for XML Schemas, following whatever schema language is eventually ratified by the W3C. Given that the Schema language should, itself, be an XML document type, an XML editor could also act as a Schema editor, although not necessarily with all the features one might desire. A WYSIWYG editor might depend on a subset of XSL for styles, or use a simpler layout mechanism, such as Cascading Style Sheets (CSS).
The next level of complexity would be an integrated Schema, document, and stylesheet editor. In such an editor, which begins to resemble an IDE, the user would be able to simultaneously change all three components. Such an editor would be extremely important from even the traditional XML publishing perspective, because changes to a Schema can have significant changes to what a document might look like.
As the workshop was focussed on XML and distributed object technologies, the most complex editing environment, with the complexity of a full IDE, would be one integrating not just the above, but also the applications which would use the XML. In such an environment it would be possible to design schemata, link them to the scripts or applications which would process them, and edit documents to be processed. This final level completes integrating the XML into the distributed object environment.
3.2 Querying
Next to editing information in XML, there is a need for interrogating structured information. During the workshop, we have identified two main areas where querying will be important:
1. data or document based searching;
2. schema based querying.
A summary of the different initiatives regarding querying XML information has been presented at QL'98 - The Query Languages Workshop, organised by the World Wide Web Consortium on December 3 and 4, 1998, in Boston [http://www.w3.org/TandS/QL/QL98/].
In the above mentioned workshop, mainly the inter-document searching has been addressed. It is important, that whatever query language initiative will eventually be standardized, one has to be able to take advantage of the structure of the information while querying. A querying language, and hence the tools implementing it, have to allow querying against content, structure (and perhaps even a meta-structure), and a combinations of these. Any querying tools should allow for easy integration with other applications, in particular distributed environments.
Another aspect of querying is based on the schema languages which are being designed in the XML world. Similar to the query languages for information searching, there is a need for a query language for interrogating XML schemas. In particular finding differences between schema languages will become important. Next to the query language(s), there is also a need for tools implementing the query model.
3.3 Storing
The discussion on storing, focussed on two modalities. One is to take the content apart and store them as objects in object-oriented databases or rows in relational databases. The other is to store them as blobs.
3.4 Transport
It would be desirable to see much more modularity in the transport layer. Though, the following discussion, uses CORBA, the same is true of DCOM. For example, CORBA --- even when construed as just the "request/reply bus" --- requires a relatively large implementation, compared to what some participants are doing instead (XML over HTTP-subset or bare TCP). The OMG has identified a "minimum CORBA" subset, but even that doesn't cut things down very much; for example, it includes the "any" data type and its (necessarily non-trivial) runtime support. And yet, there was a feeling that the various areas of concern addressed by CORBA should be disentangled. Several workshop participants said they were not using CORBA because of consequences of its monolithicity. One such consequence is the difficulty of writing an implementation, which both daunts potential direct users and limits the development of implementations for sale or share for a potential user's platform(s). Another is the runtime costs (memory, CPU) of an implementation.
A particular separation that looks interesting is between using XML for the "data" and traditional DOT for object references and invocations. For example, separating the type system from the rest of the CORBA "request/reply bus". This would provide a subset of CORBA that could transport data not usefully typed by IDL --- which is something that several workshop participants said they have. Several participants said they are not using CORBA because it is "too inflexible" --- meaning that CORBA's type system hurts more than it helps in the highly evolutionary environments at hand. Another solution to the type system inflexibility problem was also presented at the workshop: making CORBA's type system more flexible. However, that more flexible type system would still be just one point in the design space of possible type systems. Separating the type system from the rest of CORBA would enable a CORBA subset that is useful for applications where CORBA's type system --- whatever it is --- is not very good. Of course, one can always "ignore" CORBA's type system, transporting one's data as a CORBA sequence of bytes. Some workshop participants reported doing exactly this. Not all were happy with that solution --- presumably because they still have to use a whole CORBA implementation, even if they're ignoring the type system and (perhaps) using a subset of the other functionality.
3.5 Transformation
The need for transformation tools is inherently due to the nature of XML and its applications. Besides the ability to structure arbitary texutal information, XML is a powerful tool for information exchange. Therefore, information needs to be converted from a domain specific format to XML and back to another domain specific format, like the transformation of a database query result to XML and then from XML to HTML for displaying. The tools which are involved in these applications are mostly XML parsers and transformation languages such as XSLT and DSSSL. Using XML parsers has recently become simpler through the Simple API for XML (SAX) and the Document Object Model (DOM), which provide a standardized event-based and tree-based view to the incoming XML data stream. Transformation languages like XSLT can provide a fairly descriptive means to convert from XML to another representation, however, for special purposes that require calculations (e.g. page numbers, automatically generated wrapper code), programming is still needed.
Regarding distributed object computing, XML can be used for various purposes. The simplest way is to use XML as a serialization format for object exchange, an approach suggested by the WebBroker architecture. Here, the data that comprises the objects is exchanged using XML.
Object technologies and XML can also be used together on a level beyond the simple representation of an object in XML: The interface or class description itself can be represented using an XML schema such as a DTD or a RDF schema. The most generic method would incorporate the use of UML to create an object oriented model and to subsequently convert the model to the appropriate representation (IDL specifications, Java classes or XML schemata). In the case of XML schemata, this would be achieved through the use of the XML Metadata Interchange format (XMI) as the intermediate model representation, relying on transformation tools for the conversion between the UML model, the XMI representation and the corresponding XML schema.
3.6 Rendering
Tools for rendering information, usually referred to as browsers, are probably the most important part of an documentary environment (there is no point in creating information if one cannot disseminate it). In the XML world, this translates to tools which take an XML document, and present the information contained in that document in some way.
In XML (as in its predecessor SGML), the separation between structure and content on the one hand, and presentation on the other hand, is one of the fundamental principles. Hence, besides the XML document, one needs a way to model the rendering: style sheets. Currently, there are two style sheets mechanism: CSS and XSL.
Now that both CSS and XSL are gaining acceptance, there is a need for tools which support these features so that XML document that are being created can be presented to the end-users in a seamless way, without cumbersome to existing presentation tools.
4 Discussion Summary
In the following, various elements of what was discussed are presented in the form of a Frequently Asked Questions (FAQ) format.
1. What is the role of metadata management in XML and distributed object technologies?
The general feeling was metadata will become increasingly important. In particular, metadata will be important for finding definitions and using the eventual XML Schema language. Metadata management will also be more important, as will the roles of both XMI and XIF.
2. Do we need standards for "XML and distributed technologies"? If we do, which organization should standardize the specs and what should they contain? UML Class Diagrams, XML DTD's, IDL?
Standards will generally come through domain specific organizations, such as OMG’s domain task forces and HL7 (Health care). They will define their own specific DTDs or Schemas.
3. The two technologies XML and CORBA, are they synergistic or competitive? If we implement XML well, do we then delay the broad introduction of CORBA or make it easier for systems integration in the future?
They are synergistic, although there are some aspects where they might be competitive. XML was considered to work better as a messaging model for loosely coupled systems, and CORBA for tightly coupled ones. XML is used in Health Care because of lots of messaging with no existing public interfaces. CORBA, on the other hand, was considered very rigid.
4. One issue that has come up is the concern of XML processing complexity and potential large sizes of data transferred within the distributed environment. One question for example, might be: is there a need for data compression to compensate for the overhead added by the extra XML tags, etc.
This was considered a Quality of Service issue as well as an architectural one. What actual improvements compression would bring? Where would the compression go in the application, and how would interoperability be ensured. There were also questions regarding fine grained vs. large grained messages. Finally, there was mention of using isomorphisms among data representations to encode information.
5. A summary of W3C Standardization activities, their inter-dependence, and timelines for recommendations
This is best found at the W3C (www.w3.org).
6. An up-to-date summary of XML tool (parsers, authoring tools, ...) and their compliance with the various W3C standards (XML 1.0, DOM level 1, ...).
This can be found from websites such as the XML.com (www.xml.com), XML.org (www.xml.org).
7. Will XML and associated standards provide a complete solution for distributed object systems on the Web, i.e. a WebBroker strategy would be preferred over DCOM or CORBA?
WebBroker is complimentary with DCOM and Corba – it is COM/Corba using XML to marshal information as the “wire format” and HTTP in place of IIOP. As such, XML standards do provide a complete solution, but underpinning both COM and Corba.
8. Will information become generically available over the Web in XML, i.e. will all medical data be made available? What would it take?
The most important issue here is access control and security considerations.
9. Could a complete distributed medical records system be implemented on the Web that crossed institutions and provided a unique URL for a lifetime patient medical record?
The issue here is what would the business model be. If the patient owns data, then medical organizations would need to reproduce it on command. There are also trade-offs between centralized and decentralized management of the information.
10. Advantages/drawbacks of using 'lower-level' communication protocols like HTTP with XML - compared to 'higher-level' protocols such as CORBA/IIOP.
The big advantage of IIOP over HTTP is the presence of many hooks to do things in IIOP which need to be hand coded if done over HTTP. However, HTTP is much simpler to start with.
11. Different ways how XML can be tied into the object world (e.g. DOM vs. self-defined object models).
Major varieties mentioned were DOM and the SAX (Simple API for XML).
12. Is XML really the 'tool of choice' for distributed object technologies? - how can it help? - what are the shortcomings (e.g. 'un-typed' data), what extensions do we need/expect for the near future?
The W3C’s XML Schema Working Group should propose a new Schema language to handle many of the current deficiencies. There was also much discussion of the relationship among that eventual language and OMG standards, such as, UML, XMI, and the Meta Object Framework (MOF)
13. Where is XML already being successfully used? Are there any critical points where XML shouldn't be used or other techniques are better?
Successfully being used in Healthcare, push technologies (Channel Data Format, or CDF, was an early XML application), subscriptions (ICE standard), electronic commerce (numerous standards efforts currently underway), publishing. XML was considered less useful when there is no available metadata.
14. Which role can XML play in the construction and implementation of software systems (i.e. specification of interfaces, documentation, usage for actual implementation)?
All of the above.
15. Is the heavy usage of non-validated but well-formed XML somehow dangerous? are schemata and meta-descriptions the way to go or are they just too heavyweight?
Well-formed XML was considered dangerous by the group. The applicability of schemata and meta-descriptions is proportional to the scale of the application.
16. Where does XML stand with respect to databases right now? is XML easier to deploy, maintain and use compared to database technology?
XML was considered easier to use than database technology.
17. Exceptions on Schema
The issue was raised as to defining exceptions in the Schema language. It was generally considered that parsers would need to report invalid documents (ones not conforming to their schema), but that this could come from a standardized set, and the ability to define exceptions was not required for the schema language.
18. Will XML ever replace HTML? Is XML for end users or for programmers?
It was not thought that XML would completely replace HTML, although well-formed HTML may become more and more present through its generation by editing tools, even if it never completely replaces HTML for hand-coded pages. XML was considered of use to both end users and programmers.
5 Conclusions
In a distributed computing context, XML focuses on exchange of structually rich data more than traditional object-oriented (and computation-centered) technologies like CORBA and DCOM. We found that this presents a fresh viewpoint on some of the issues surrounding distributed objects. Much of XML's promise, from the workshop's point of view, rests with an improved XML Schema language. Having a strong tie to UML modelling, widely used in OO design, sidesteps many of the problems with hand-coded mappings, and allows data to be validated by the receiver -- an important feature of typed XML documents. Tool support for XML is already significant, and we expect to see a lot of common developer issues addressed in the near term as standards solidify. Next year, we hope to look more closely at applications that use XML in a distributed objects application, and examine the interaction of these technologies in more detail.
6 Alphabet Soup
CORBA Commob Object Request Broker Architecture: http://www.corba.org/.
CSS Cascading Style Sheets http://www.w3.org/Style/.
DOM Document Object Model http://www.w3c.org/TR/REC-DOM-Level-1/; http://www.w3.org/DOM/;
DCD Document Content Description
DCOM Distributed Component Object Model
DTD Document Type Definition
EJB Enterprise Java Beans: Server-side Component Specification from Sun Microsystems: http://www.javasoft.com/products/ejb/docs.html
HTML Hyper-Text Markup Language. http://www.w3.org/MarkUp/
HTTP Hyper-text Transfer Protocol. http://www.w3.org/Protocols/.
HTTP-NG Hyper-text Transfer Protocol-Next Generation. http://www.w3.org/Protocols/HTTP-NG/.
IIOP Internet Interoperable Protocol, OMG’s standard transport protocol. http://www.omg.org/cgi-bin/doc?formal/97-02-25.
MCF Meta Content Framework http://www.textuality.com/sgml-erb/w3c-mcf.html.
MOF Meta Object Facility
OIM Open Information Models – Microsoft Specification for representation and exchange of metadata. http://msdn.microsoft.com/repository/oim/strategy.asp.
OMG Object Management Group http://www.omg.org/
RDF Resource Description Framework
RMI Remote Method Invocation. http://java.sun.com/products/ JDK 1.1.x/1.2 includes RMI
RMI over IIOP is based on two specifications of the OMG:
Java-to-IDL mapping, Objects-by-Value - see: http://java.sun.com/products/rmi-iiop/
RTIM - what's that?
SAX API http://www.microstar.com/sax.html
UFDL Universal Forms Description Language
UML Univesal Modeling Language, a specification for modeling standardized by OMG: http://www.omg.org/techprocess/meetings/schedule/Technology_Adoptions.html#tbl_UML_Specification.
W3C World Wide Web Consortitium. http://www.w3c.org/
WEBDAV http://www.ietf.org/html.charters/webdav-charter.html; http://www.ics.uci.edu/pub/ietf/webdav/; http://www.webdav.org/
XFDL eXtensible Forms Description Language. W3C Note, September 1998. http://www.w3.org/TR/NOTE-XFDL
XIF Microsoft XML Interchange Facility: www.microsoft.com/repository
Xlink http://www.w3.org/TR/WD-xlink.
XMI XML Metadata Interchange (XMI) Proposal to the OMG OA&DTF RFP 3: Stream-based Model Interchange Format (SMIF). http://www.omg.org/cgi-bin/doc?ad/98-10-06.
XML XML Linking Language. http://www.w3.org/XML/;
XML Schema: XML Schema Part 1: Structures http://www.w3.org/TR/xmlschema-1/ XML Schema Part 1: Datatypes http://www.w3.org/TR/xmlschema-2/
Xpointer XML Pointer Language. http://www.w3.org/TR/WD-xptr
XQL XML Query Language http://www.w3.org/TR/NOTE-xml-ql/
XSL http://www.w3.org/Style/; http://www.w3c.org/TR/WD-xsl;
XUL - Extensible User Interface Language (part of the Mozilla project) http://www.mozilla.org/xpfe/languageSpec.html